An index is a virtual record, set to make data retrieval quicker. When you apply an index to a column, R:BASE records the location of every value in that column. Then, when you look for or sort information in the column, R:BASE uses the index to find the rows you need quickly.
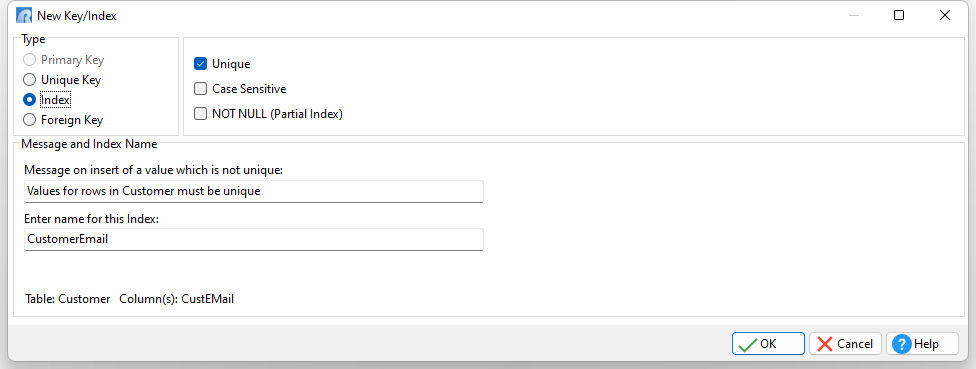
Unique - specifies that the data values MUST be unique
Case Sensitive - specifies that the data values will be case sensitive
NOT NULL - specifies a not NULL (partial) index is created. The index is populated with references to rows where the column value is not NULL. NULL values in the column are not added to the index. Not NULL indexes are ideal for columns which contain a considerable amount of NULL values, and where the not-NULL data is ideal for index retrievals. If a WHERE clause includes "ColName IS NULL" then the index is not used. When a NOT NULL index is created, the "Attributes" column will list the definition.

Message and Index Name
Message on insert of a value which is not unique - the message that will be displayed to a user attempting to insert a row with a field value which already exists in the table. When the "Unique" check box is checked, this message box is enabled. A default message is provided, and can be changed only when the key is created.
Enter name for this Index - a 1-128 character alpha-numeric name for the index. Valid names must start with an alpha character and can include the following symbols: Letters (A-Z); Numbers (0-9); # (pound sign); _ (underscore); $ (dollar sign); % (percent sign). Spaces are NOT permitted. A default value consisting of the table name and column name is provided when creating a new single-column index.
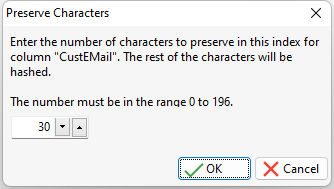
Text Column Indexes
When you are adding indexes based upon TEXT data type columns, you will be prompted to specify the number of characters you wish to preserve for the index.
After the index definition is complete, the index name, column(s), duplicate factor, and adjacency factor are displayed in the Data Designer window. Once the index is selected, the "Column(s)" panel displays the column(s) that the index is based upon and the sorting order. If the index is based on a TEXT column, the text length is also provided. If the index is defined to only accept unique values, the unique value enforcement "Message" is also listed when the index is selected.
Duplicate Factor - the computed duplicate factor used by R:BASE during retrieval to guess the fastest way to find the result set. This number is the average number of times each value appears in the column. A number of 1.0 means that values are never duplicated, or always unique. Zero means that the value is unknown. The higher the number, the less efficient the index.
Adjacency Factor is the computed adjacency factor used by R:BASE during retrieval to guess the fastest way to find the result set. It is the estimate of the probability that two rows with similar index values will be physically located together in data file (.RX2). A higher number means more efficient retrieval when reading rows in index order. Zero means that the value is unknown.
The duplicate and adjacency factor values are computed when indexes are first created and when rebuilt or reloaded, during a PACK or RELOAD.
See Also: