Use the CREATE INDEX command to speed up data retrieval by creating pointers that locate rows in a table easily.
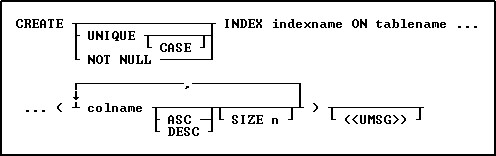
Options
,
Indicates that this part of the command is repeatable.
ASC
DESC
Specifies whether to sort a column in ascending or descending order.
CASE
Specifies that the data values will be case sensitive.
colname
Specifies a column name. The column name is limited to 128 characters. In a command, you can enter #c, where #c is the column number shown when the columns are listed with the LIST TABLES command.
INDEX indexname
Specifies an index, which is displayed with the LIST INDEX command. An indexname is required.
NOT NULL
Specifies a not NULL (partial) index is created. The index is populated with references to rows where the column value is not NULL. NULL values in the column are not added to the index. Not NULL indexes are ideal for columns which contain a considerable amount of NULL values, and where the not-NULL data is ideal for index retrievals. If a WHERE clause includes "ColName IS NULL" then the index is not used.
ON tblname
Specifies the table in which to create an index for a column.
SIZE n
Sets the minimum number of characters to preserve to determine uniqueness during hashing. This number can be a maximum of 196 characters. The index is created with the first n characters preserved and the rest of the value stored as a 4-byte hashed representation.
UNIQUE
Requires the values in a column to be unique.
(<UMSG>)
Creates a constraint violation message to appear whenever a unique index data integrity violation occurs. The message can suit the meaning of your data, such as "You must enter a unique number" for a unique index constraint violation. The index must be dropped, then recreated in order to modify the violation message.
About the CREATE INDEX Command
An index creates pointers to rows in columns, which allows R:BASE to find the rows using pointers much faster than searching the rows of data sequentially. You can index a column of any data type. An indexed column improves the performance of the following commands, clauses, and operations.
Commands, Clauses, and Operations to Use with Indexes |
|
SELECT (when it includes a WHERE or an ORDER BY clause) |
|
Look-up expressions in Forms or Reports |
|
Although indexes speed up processing, they might slow down data entry because building an index for each value as it is entered takes time. Creating indexes for columns that contain many duplicate values does not always speed up processing. Indexes also occupy space on a disk.
Null Values
An indexed column can contain null values, but R:BASE uses an index most efficiently if each row in the indexed column contains a value. Primary keys, unique keys, or unique indexes explicitly restrict the insertion of null values. For other indexes, you can define a rule to ensure that a column always contains a value. A Not NULL index may also be defined for columns where many NULL values exist.
UPDATE Permission
When access rights for a table have been assigned using the GRANT command, you must have UPDATE permission for the column you want to index.
Indexing Criteria
Some columns are better candidates than others for indexing. To receive the greatest benefit from indexes, use the following criteria to help you decide which type of column is the best choice for indexing your table(s):
Primary Key
R:BASE automatically indexes the column(s) that is defined as the table's primary key.
Foreign Key
R:BASE automatically indexes the column(s) that is defined as the table's foreign key.
Columns Used in Queries
Columns that are not primary or foreign keys but are frequently used in queries should be indexed. Create a unique key constraint for columns that are not primary or foreign keys, but which uniquely identify a row in the table.
Columns Frequently Using ORDER BY or GROUP BY
Include a column in an ascending-order index when the column is not a primary or foreign key but is frequently referenced in an ascending-column ORDER BY or GROUP BY clause. Similarly, include a column in a descending-order index when the column is frequently referenced in a descending-column ORDER BY clause.
Full- and Partial-Text Indexes
Text columns can make effective indexed columns. If the size of the column that has a TEXT data type is 200 bytes or less, R:BASE creates a full-text index. A full-text index is an index that stores the entire contents of a column as an index in File 3, which is the file that contains indexes to columns. If the size of the column is greater than 200 bytes, R:BASE creates a partial-text index.
If you specify the SIZE option to be less than the defined length of a column, R:BASE creates a partial-text index, and any text column that has a defined length over 200 bytes must be a partial-text index. For columns that have a TEXT data type and exceed 200 bytes, you can specify the SIZE option to be between 0 and 196 to create a partial-text index. Specifying the size allows you to base your index on a specified number of characters at the beginning of the columns and to hash the remaining characters. For example, you can index a 225-character column with a TEXT data type by specifying the SIZE option to be any number less than 197 bytes. R:BASE will create an index with the first n characters and the rest of the value will be stored as a four-byte hashed representation of the text.
Partial-text indexes minimize storage space. However, partial-text indexes might not be as efficient as a full-text index, for example:
CREATE TABLE Cities (CityName TEXT(40), State TEXT(2), Country TEXT(20))
CREATE INDEX CityIndex ON Cities (CityName, State)
INSERT INTO Cities VALUES('Bellevue','WA','USA')
INSERT INTO Cities VALUES('Belltown','PA','USA')
SELECT CityName, State from Cities WHERE CityName = 'Bellevue'
In the above example, because the query reads data only from the index named CityIndex, there is no need to read the actual data stored in File 2-which is the data file-so the query is done quickly. The query is an index-only retrieval and produces fast results.
If a partial-text index was used in the same query as above, the partial-text index could also only use the index named CityIndex. Because the partial-text index only preserves the first four characters, it is impossible to return the correct answer to the query from the index. The query, as shown below, would slow processing because R:BASE must read data from the R:BASE data file.
CREATE INDEX CityIndex ON Cities (CityName SIZE 4, State)
SELECT CityName, State from Cities WHERE CityName = 'Bellevue'
When creating text indexes, be aware of the following:
•If you omit the SIZE option and the text field in the column is greater than 200 bytes, R:BASE creates a partial text index by storing the first 32 bytes of each field and hashing the remaining bytes in each field into a four-byte numeric representation of the text. For example, if the text is 280 bytes and you do not specify a size, R:BASE stores the first 32 bytes of each field and hashes the remaining 248 bytes into a four-byte integer.
•If you specify the SIZE option to be 16 bytes for a 60-byte column with a TEXT data type, R:BASE stores the first 16 bytes of each 60-byte text field and hashes the remaining bytes in each field into a four-byte numeric representation of the text. The total length of each index entry will be 20 bytes (16 + 4).
•If you specify the SIZE option to be 30-bytes for a 250-byte column with a TEXT data type, R:BASE stores the first 30 bytes of each 250-byte field and hashes the remaining bytes in each field into a four-byte numeric representation of the text. The total length of each index entry will be 34 bytes.
•If you specify the SIZE option to be 250 bytes for a column with a TEXT data type, you have made an illegal request because the maximum value for the SIZE option is 196 bytes when the length of the text field is greater than 200 bytes. If you specified the SIZE option to be 196 bytes for a 250-byte column, R:BASE would hash the remaining 54 bytes into a four-byte numeric representation of the text.
•If you omit the SIZE option and the text field in the column is 200 bytes or less, R:BASE creates a full-text index. For example, if the text is 80 bytes and you do not specify a size, R:BASE builds a full-text index of 80 bytes.
MICRORIM_INDEXLOCK
The system variable, MICRORIM_INDEXLOCK, is available to control concurrency locks for the CREATE INDEX command. This variable prevents CREATE INDEX from holding a permanent database lock. It locks only as necessary, allowing users access to the database. This results in longer index creation time but greater concurrency. MICRORIM_INDEXLOCK is set to any integer value.
Examples
The following command creates an index for the CustID column in the TransMaster table.
CREATE INDEX TranCust ON TransMaster (CustID)
The following example creates a multi-column index for the Company, CustAddress, and CustState columns in the Customer table.
CREATE INDEX CustAddr ON Customer (Company ASC, CustAddress ASC, CustState ASC)
The following example creates a unique index for the TRStockID column in the TStockHeader table.
CREATE UNIQUE INDEX TRSID ON `TStockHeader` (`TRStockID` ASC ) +
('Values for rows in TurnRoundID must be unique!')
The following creates a not NULL index for the DiscontinuedDate column in the Products table.
CREATE NOT NULL INDEX DiscontDate ON Products (DiscontinuedDate DESC)