To assist in determining the efficiency of indexes, check the Duplicate Factor and Adjacency Factor values within the Data Designer.
For Duplicate Factor, this is the average number of times each value appears in the column. The number 1 means that values are never duplicated, or unique. The "higher" the number, the less efficient the index.
For Adjacency Factor, this number is the estimate of the probability that two rows with similar index values will be physically located together in the #2 data file. A "higher" number means more efficient retrieval when reading rows in index order.
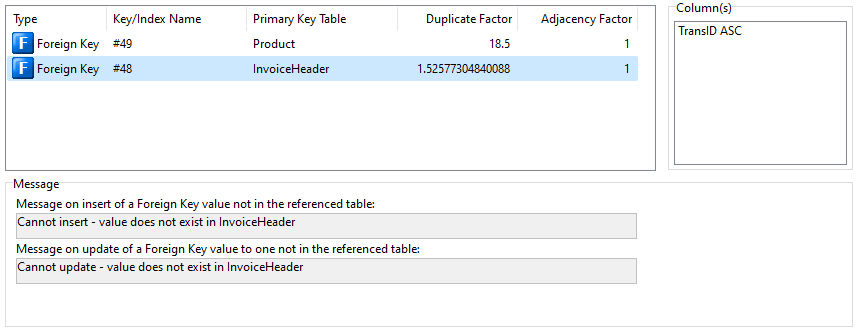
Duplicate Factor is the computed duplicate factor, used by R:BASE during retrieval to guess the fastest way to find the result set. This number is the average number of times each value appears in the column. A number of 1.0 means that values are never duplicated, or always unique. Zero means that the value is unknown. The higher the number, the less efficient the index.
Adjacency Factor is the computed adjacency factor, used by R:BASE during retrieval to guess the fastest way to find the result set. It is the estimate of the probability that two rows with similar index values will be physically located together in the .RX2 file. A higher number means more efficient retrieval when reading rows in index order. Zero means that the value is unknown.
The values within these two columns are computed when indexes are rebuilt or reloaded, for example, during a PACK or RELOAD.
It is recommended that you reconsider the use of indexes with a high Duplicate Factor value. But, there is not an exact Duplicate Factor benchmark for which to warrant its value "too high". It's value is calculated based upon the number of duplicate values that are within the column, which would be directly related to how many rows are in the table.
A Duplicate Factor with a value of 500 within a table containing 750 rows would be an example of a poorly implemented index. On the other hand, a Duplicate Factor of 500 within a table containing 785,000 rows would be considered productive. The Duplicate Factor value is used by R:BASE to guess the fastest way to find your results. The recommendation to reconsider the use of indexes with a high Duplicate Factor value is just that; a recommendation. It is up to the developer to decide if they are truly taking advantage of the index, or hurting their system's performance.